
Introduction
This is the third post in my series of reflections from my co-op terms. After spending my previous co-op term on the Cash App Product Platform term, I was thrilled to accept a return offer to work with the Availability Team based out of Toronto.
Who are Square and Cash App?
You didn’t read my previous blog post? Here’s the gist!
Square is a FinTech company headquartered in San Francisco. You probably know them best for their credit card readers that plug into your iPhone, or their beautiful point of sale systems you see in trendy, independent cafés.
Cash App is an organization within Square, which operates a suite of personal financial services in the US and UK markets. These services include peer-to-peer payments, direct deposit accounts, stock and bitcoin investing, among others. The app has seen tremendous growth over the past year, and while no one could have predicted it — it also played a big role this April in helping American citizens get access to their stimulus cheques as part of COVID-19 economic relief efforts.

Cash App government stimulus payment promo.
Cash App Availability
The Cash App Availability Team focuses on scaling our services so that we can be highly available while sustaining high volumes of customer traffic.
On a high level, some priorities and tasks on this team include
- MySQL database scalability and Vitess operation
- Load and capacity management in our data centers for app and job hosts
- Metrics observation and response
Expectations
As part of the availability team, I expected to experience a very back-end heavy term, with a mixture of ops and software development.
This past Fall semester, I took a couple helpful courses that provided me with the knowledge and confidence I needed to excel over this term: CIS*3530 (Database Systems and Concepts) taught by Dr. Fangju Wang, and CIS*3760 (Software Engineering) taught by Dr. Judi McCuaig. Understanding that the Cash App availability team has a focus on database engineering, scaling, and operation, the theory taught in these courses helped me to quickly grasp database concepts used in Cash App production systems, and to better understand the measures and metrics that are so tightly associated with their operation. In turn, I expected my work to reinforce these learnings.
Returning to Cash App, I had a big advantage as I was already familiar with the technologies I would be working with, so I expected to ramp up very quickly. Moreover, my last term was spent building and maintaining features of our service framework, Misk — and at Cash App, engineers are empowered to push helpful changes down to the platform, so I expected to work productively with a high level of confidence.
What did I do?
It’s no secret that humans are creatures of habit and routine. There are certain times of the month that always have high financial activity — paydays, the beginning of the month when rent is due, Friday hangouts with friends. As a peer-to-peer payments product, Cash App gets hit harder at these times, and as Cash App grows, we need to have an understanding of how our services handle these increasingly large spikes of traffic. The worst thing that could happen would be if we were caught by surprise and our users DoS’d our own services! We absolutely do not want this to happen.
To that end, our team is motivated to simulate high traffic situations to figure out weak-points and bottlenecks of our systems so that we can fix things well before they actually break.
In the past, we’ve forecasted capacity and traffic issues by intentionally reducing capacity (e.g. by artificially making hosts unavailable to serve traffic) in order to simulate high load. This is not ideal for a number of reasons:
- In these situations, we can’t control the traffic volume.
- Intentionally reducing capacity means we have to be extremely careful not to affect customers.
- The results from these tests need to be scaled to estimate the max traffic we can serve at our current capacity.
- With high growth, the conclusions drawn from these tests become outdated relatively quickly.
To address these concerns, this term I built out a service called Shadow which is capable of generating high volumes of traffic on demand. The goal: when we are serving low volumes of traffic from real customers, we can generate high volumes of fake traffic — allowing us to get a more accurate read of our capacity to serve traffic for the next anticipated spike of activity.
As the term went on, Shadow matured quickly. It started as a limited scope system that could send payments between test customers, and grew into a general framework that can be leveraged to load test arbitrary service endpoints. Its scope expanded to serve as a client for live integration tests, and there is a proposal for some exciting expansions to its functionality with ML-based traffic models.
Goals
Over the course of this term, I identified five main goals, outlined below. These goals capture some main themes from the term, but cannot possibly capture the full extent of my learnings.
- Improve understanding of use and implementation of software metrics
- Rapidly iterate and realize prototypes
- Contribute reusable solutions to upstream code
- Better understand large-scale organizational infrastructure
- Understand mitigation strategies for critical failures in production
These goals were identified to enhance my skills in building and operating software at scale. Each of these goals were achieved, and related learnings are described below.
Learnings
Software metrics
Watching anyone on our team do their work for the first time is a fascinating experience. Picture an ultra-wide curved monitor packed with live charts and metrics — it’s a beautiful and overwhelming thing. These metrics provide an insight into the health and complexity of an important distributed system, and they are totally Greek at first exposure. It was a requirement of my experience on this team to understand how to identify patterns out of these charts, to understand which metrics are most important, and how to manipulate these views to get a picture of the health and performance of our production software. Understanding the links between traffic volume and JVM pause time, latency, and job consumption is fundamental — and it’s something I had little exposure to before this work term.
For this term, I wanted to use metrics to drive decisions and develop a deeper understanding of our systems. By the end of April, we were running semi-regular load tests with Shadow, and Shadow was itself consuming capacity-related metrics so it could automatically scale back traffic as a safety measure. Having become familiar with monitoring tools like SignalFX, and key capacity-related metrics, I am much more confident in my ability to make data-driven decisions, and to identify software performance issues.
Rapidly building software
At the start of this term, Shadow was a minimal viable product. It could call into a special endpoint to test payment logic between customers belonging to a fake region, so as not to affect any real customers or business metrics. It didn’t have a UI, and it was limited in scope. By the end of this term, Shadow was able to run load tests against arbitrary Cash App services.
To bring a project into a mature state, it was extremely important to do so in small, manageable chunks. About a week into my term, my first pull request hooked up a basic UI to the service. Regular changes eventually generalized the service, added a complete UI, overhauled the application architecture to work on AWS Job Queues, and created type-safe APIs. Regular demos generated interest in the project from other teams, and it wasn’t long before Shadow integrated with other services and we received feature requests.
Working closely with my mentor Valerio, I’m proud of how the service has grown over the past four months.
While line counts and git commits are flawed measures at best, for a rough measure of this achievement — as of April 29 — I had made more than 90 pull requests to the Shadow repository over approximately 80 working days on the project.
When I started on the project, Shadow’s code base looked something like this:
valerio.fix-enabled-loaded
$> tokei -t="Kotlin,TypeScript,Protocol Buffers,SQL,YAML" .
-------------------------------------------------------------------------------
Language Files Lines Code Comments Blanks
-------------------------------------------------------------------------------
Kotlin 43 1927 1622 43 262
Protocol Buffers 1 43 34 1 8
SQL 6 40 40 0 0
TypeScript 127 1662 1200 462 0
YAML 7 106 96 2 8
-------------------------------------------------------------------------------
Total 184 3778 2992 508 278
-------------------------------------------------------------------------------
And at the time of writing, Shadow’s code base looks like this:
master
$> tokei -t="Kotlin,TypeScript,Protocol Buffers,SQL,YAML" .
-------------------------------------------------------------------------------
Language Files Lines Code Comments Blanks
-------------------------------------------------------------------------------
Kotlin 160 9556 7723 472 1361
Protocol Buffers 1 82 68 1 13
SQL 30 150 150 0 0
TypeScript 44 3474 2970 157 347
YAML 7 139 125 2 12
-------------------------------------------------------------------------------
Total 242 13401 11036 632 1733
-------------------------------------------------------------------------------
It’s grown a lot (~10 KLoC!), and I’m excited to have built up the service as quickly as we did!
Upstream contributions
One of the simplest and most important principles of software development that I’ve learned from my time at Cash App is that if you have a common platform, it should be a place for sane and good defaults. As such, it’s important to push as much as possible down to the platform so that others can benefit from your changes.
While I didn’t work directly on the platform this time around, I discovered some exciting changes in my work on Shadow, which ended up there anyway. These contributions resulted in better performance for all Cash applications that use the open-source Misk service framework. Misk now uses gzip encoding for web responses by default, so that our apps can enjoy smaller and faster responses, and our database entities perform better as a result of adding some compiler plugins.
I’m happy to have contributed and improved the situation.
I also contributed some code upstream to a third-party repository, to improve the testability of a vtcompose, a script which is used to set up Vitess clusters with Docker-compose. While this was lower priority work, I was happy to write a bit of Golang for the first time in a couple years.
Operating at scale
What does software look like when it has to scale to serve 24 million monthly active users? 1
Software this big comes with a lot of complexity, and there are operational constraints for just about every component of the system. These constraints need to be met for the system to be healthy and reliable.
One of the most well known problems with operating Cash App at scale is scaling its databases. There’s a series of blog posts on the Cash App Engineering blog that go into more detail, but before this term I hadn’t really experienced what that looked like concretely.
As software matures, its database grows. As a database grows, its performance worsens. At Square, the size limit for a database tends to be around 1TB of data before performance starts to drop off. 2 After you’ve taken into consideration other performance operations like caching and query operation, it’s at this point that you want to consider a sharding your database — that is, splitting up your data so it can be hosted from multiple databases. This is done to keep database sizes at an acceptable limit, and provide more room for growth.

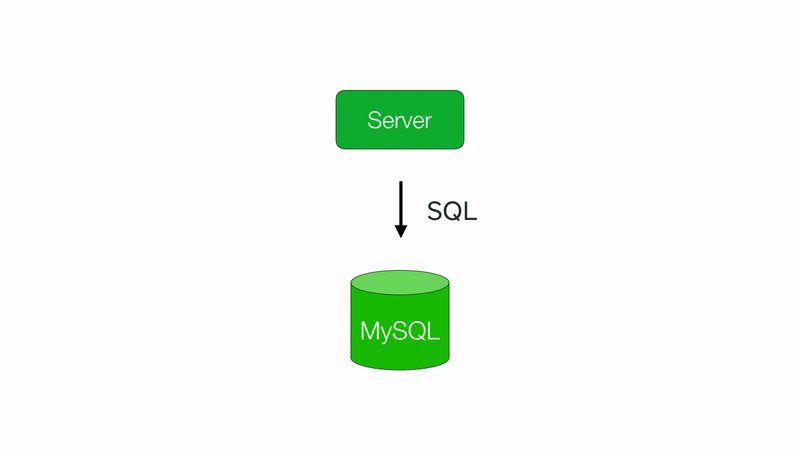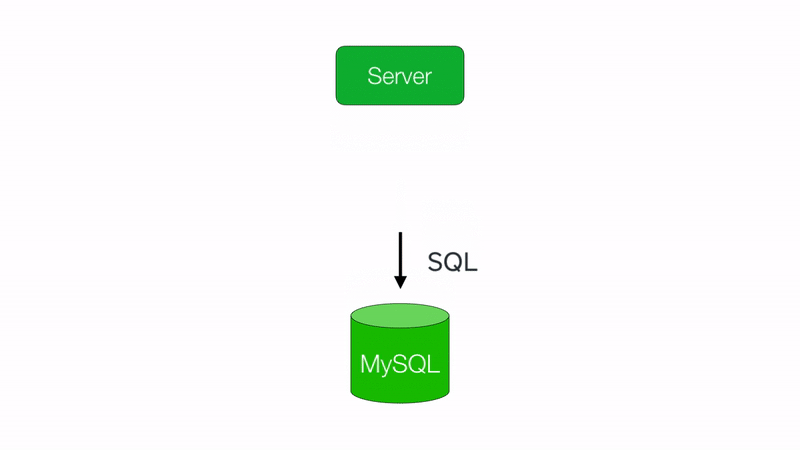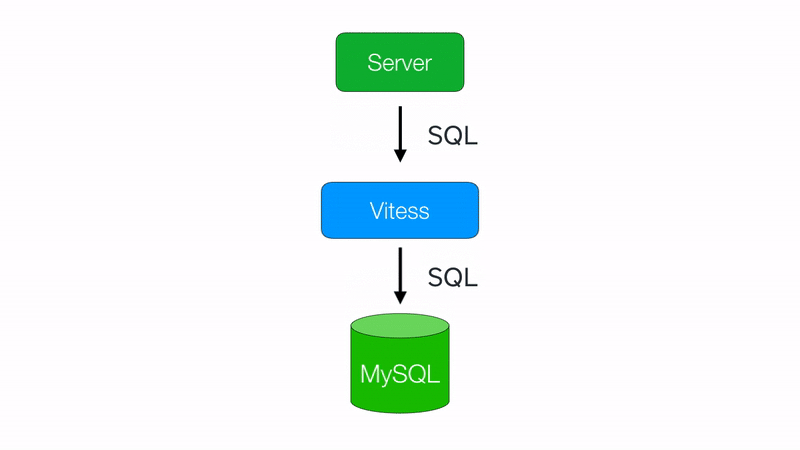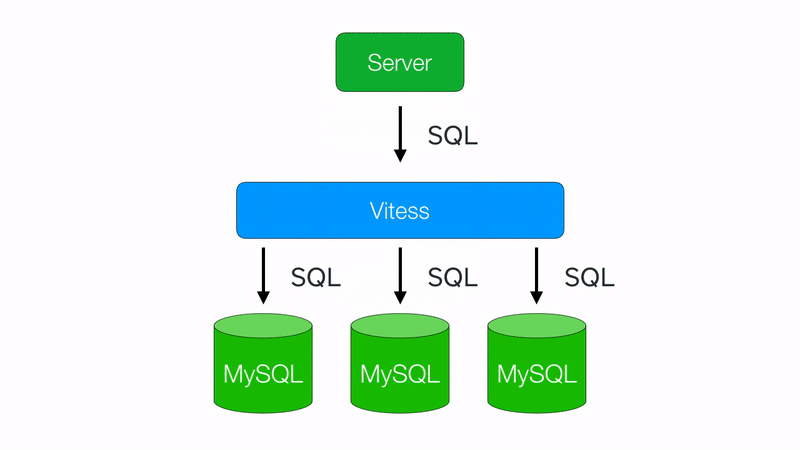
This doesn’t come for free though! Routing queries to the correct database is non-trivial, so this is where Vitess comes in handy. Vitess operates as a layer between your application server and your sharded databases, providing efficient query routing with minimal application changes.
Through this term, I shadowed a vertical split of some database shards, read up on splitting theory, and generally gained a better of understanding of how this process works. I now have much more confidence with these systems, and I’m excited to continue to learn about software performance and scaling as I finish up my computer science degree.
Mitigating production failures
Cash App operates financial services, which means that we need to be highly available and consistent. Failures are a reality of software engineering, and this term I wanted to better understand how these are mitigated — both technically and operationally. While I had a general sense of how this was handled before I started my term, working with the Availability team gave me a deeper sense of understanding. Through this term, I learned about concurrency shedding, side effects of certain errors and loads on our systems, and how this can impact customers.
On the operational side of things, on-call schedules are very important for monitoring and keeping Cash App services healthy. While interns are not allowed to join on-call schedules at Square, I wanted to have a better understanding of how what on-call is like, so I sat in on some post-mortem meetings about production failures, and participated in some on-call discussions. From these discussions, it was clear that the tool we had developed this term could be useful for on-call, so we pushed to make Shadow safe and easy to use for this purpose. Failure mitigation was a key consideration in this term’s design and development, and Valerio and I have demonstrated how Shadow can be used in staging to test for errors in hot end-points. By the end of April, our service has been used to catch at least two severe bugs in staging, and it has met with enthusiasm by engineers in the on-call rotation.
I'm happy to have an improved understanding of on-call procedures, and that my tool may improve some parts of the situation.
Takeaways
As expected, working with the Cash App team was an incredibly rewarding, educational, and fun experience this term. It’s incredible to see how much the team has grown since last summer, and how Cash App growth continues on such an upward trajectory. Operating at scale and moving to the cloud is no simple process, but Cash does it well, and I continue to be impressed by our engineering practices.
I’m super happy with what I managed to accomplish this term, and I’m very excited to see Cash App and Square continue to grow their presence in Toronto. There are some exciting days ahead for Cash, and I’ll be following as closely as I can during my final year of studies!
If you’re as interested in this team as I am, Cash App is currently hiring in Kitchener, Toronto, and around the globe.
Big kudos
My time interning this winter with Cash App engineering was a fantastic experience which presented new learning opportunities and challenges each day, just as it was last summer. My successes and learnings over these past four months can very much be attributed to my peers and mentors from the Availability team.
Square has a culture of giving kudos, and so some kudos are well-deserved!
Kudos go to Aaron Young, Valerio Pastro, Mike Pawliszyn, Lloyd Cablanca, Javier Ruiz, and Mike Lovelace for being such an excellent team, and maintaining a fun and enjoyable work environment — even during a pandemic.
Kudos to Andrew Alexander and Alex Szlavik for helping me learn the ins and outs of React-redux — without your help, building a usable UI for Shadow would’ve been a lot harder! ✨
Kudos and extra special thanks go to Sumair Ur-Rahman for guinea-pigging the first integration with Shadow, and for catching a couple SEV-worthy bugs as a result! 💥
Another round of kudos go to the Carolynn Choi and the rest of the campus team for ensuring this term went smoothly and was never short of intern-focused events and presentations 🙌
Lastly, king kudos go to Aaron and Valerio for their mentorship throughout this term, and for presenting new opportunities to learn whenever they came up! 🔥
PS: A new normal
This term has left me humbled as a software engineer.
In the midst of the outbreak of a global pandemic, I cannot help but feel extremely fortunate that in this profession, my day to day tasks are very well suited to remote work.
To the surprise of many of my friends and family, I began working from home full time in mid-February as a result of an aggressive global company policy change. Square responded extremely proactively to COVID-19, strongly recommending and even requiring engineers to work from home — well before social-distancing and shelter-in-place orders were place in Canada and the US.
I would be ignorant if I did not call out the fact that I am lucky to have an employer that cares so tremendously about the health of its employees. Remote work became the new normal for us — and it eliminated any risk of exposure I would have had commuting on the TTC Subway.
In these trying economic times I have always felt like we were put first… while the pandemic shocked so many other companies. In the same vein, I am so happy and thankful that for my upcoming summer work term, Mozilla is continuing with their internship program in a fully remote format.
All graphics in this article are courtesy of Square Inc.
-
Q4 2019 Shareholder Letter, Square. https://s21.q4cdn.com/114365585/files/doc_financials/2019/q4/2019-Q4-Shareholder-Letter-Square.pdf ↩︎
-
Sharding Cash, Cash App Code Blog. https://cashapp.github.io/2018-11-07/sharding-cash ↩︎